Appearance
HTML
HTML ist eine Dokumentbeschreibungssprache (keine Programmiersprache). Ähnlich wie XML arbeitet HTML mit Tags (auch HTML Elemente genannt) <tag></tag>, hierbei wird der Tag geöffnet und wieder geschlossen. Tags können Attribute beinhalten, wie das z.B. beim meta Tag ersichtlich ist.
Tags können auch kurz geschlossen werden, wie z.B. <script src="./main.js" /> im Gegensatz zur langschreibweise <script src="./main.js"></script>.
Ausnahmen
Es gibt einige Tags, die nicht wie in XML üblich geschlossen werden (z.B. <link>, <input> und <img>).
Tags können "nested", also verschachtelt sein. Man redet von einer Baumstruktur oder auch vom HTML "DOM", also dem HTML-Bau (Tree). Eine gültige HTML Seite hat dabei genau einen html Tag. Der html Tag hat genau einen head und genau einen body tag.
Der Inhalt des head Tags wird hierbei als erstes geladen und verlinkte Resourcen heruntergeladen, bevor der body Tag vom Browser gerendert wird. Im Head findet man neben Styling (css) und Java Script (js) auch Metainformationen für den Webbrowser oder auch Suchmaschinen, die nach meta Informationen suchen.
HTML schreiben und testen
Um HTML schreiben und testen zu können, reicht ein Texteditor und Webbrowser aus.
HTML braucht keinen Compiler und kann als File direkt vom Webbrowser interpretiert werden. Sogar Javascript kann als Scriptsprache ohne Compiler vom Browser ausgeführt werden.
Es gibt natürlich auch für Javascript Compiler, welche optimierten Code erstellen. Alternativ kann der Browser als VM für Webassembly verwendet werden (z.B. via Rust).
Um mit HTML, CSS und JS loszulegen reicht allerdings ein Texteditor und Webbrowser völlig aus.
CSS
Cascading Style Sheets erlauben es HTML zu formattieren und dabei sogar den Layout Manager von Elementen grundlegen zu ändern. So können zwei Webseiten, die den gleichen HTML DOM besitzen völlig unterschiedlich aussehen.
Interpretation von HTML
HTML wird vom Webbrowser, sowie auch von Suchmaschinen und Crawlern im Netz interpretiert. Häufig wählt man einen strukturierten Ansatz um die Webseite zu gestalten (zum Beispiel hirarchisch).
So verwendet man meistens Überschriften wie <h1>Titel</h1> für einen Titel und <h2>Untertitel</h2> für einen Untertitel.
Für Text wird häufig ein Paragraph <p>Das ist ein Fliesstext.</p> verwendet.
Hier sind oft verwendete HTML Elemente:
| Element | |
|---|---|
<div> | Generisches Block Element |
<a href=".."> | Hyperlink |
<img src=".."> | Bildresource |
<p> | Paragraph für Fliesstext |
<span> | Inline Element für Text |
<table> | Tabelle |
<script> | Java Script / ES6 |
<style> | CSS Styling, nur im <head> |
<input> | Form Input |
<ul>, <li> | Liste / Aufzählung |
<div> der Alleskönner
Der <div> Tag ist ein völlig generischer Tag, welcher sich via Cascading Style Sheets (css) nach belieben "stylen" lässt. Defaultmässig wird er als block gerendet. Häufig wird er auch mit der CSS Display Property flex oder grid gesehen.
Der <div> selber hat demnach nur wenig Aussagekraft, über wie der Block und dessen Inhalte auf dem Bildschirm dargestellt werden.
Wichtig ist es zu verstehen, dass <div> Elemente beliebig verschachtelt werden können und es dabei vom CSS abhängt, wie die Struktur vom Browser im Viewport gerendert wird.
Sie könne hier eine Parallle zu Java und den Layout Managern ziehen (GridBag, Absolute, Flow, ...), welche bestimmen, wie die Elemente, welche einem Panel hinzugefügt werden gerendert werden..
HTML5 und Semantic Elements
Für den Leser des Source Codes ist ein <div> nicht wirklich vielaussagend. Genau so wie Variabelnamen eine wichtige Bedeutung für das Verständnis und Wartbarkeit von Source Code spielen, ist es auch hilfreich, sich in HTML zurechtzufinden.
Mit HTML5 wurden neue Elemente definiert, die einen semantischen Charakter haben. Anstelle von <div> und <span> findet man deklarative Elemente wie <article>,<section>, <aside>, <details>, <figure>, <nav>, <summary> etc. . Diese Elemente haben keine strikte Regeln, wie Sie angeordnet und strukturiert werden müssen. Sie helfen dem Leser des Sources zu verstehen, welche Bedeutung die Elemente im Kontext haben (im Gegensatz zu reinen <div>s).
Ein weiterer Vorteil (je nach Standpunkt ev. sogar Nachteil) dieser Elemente besteht darin, dass Webcrawler besser in der Lage sind den Inhalt selber einfacher zu interpretieren und neu darzustellen (Beispiel Newsreader).
Näheres zu den Elementen finden Sie unter folgendem Link: https://www.w3schools.com/html/html5_semantic_elements.asp
Eine erste Webseite
Erstellen Sie eine Webseite, die folgendermassen aussieht, basierend auf dem Template, welches Sie in VS Code bereits erstellt haben:
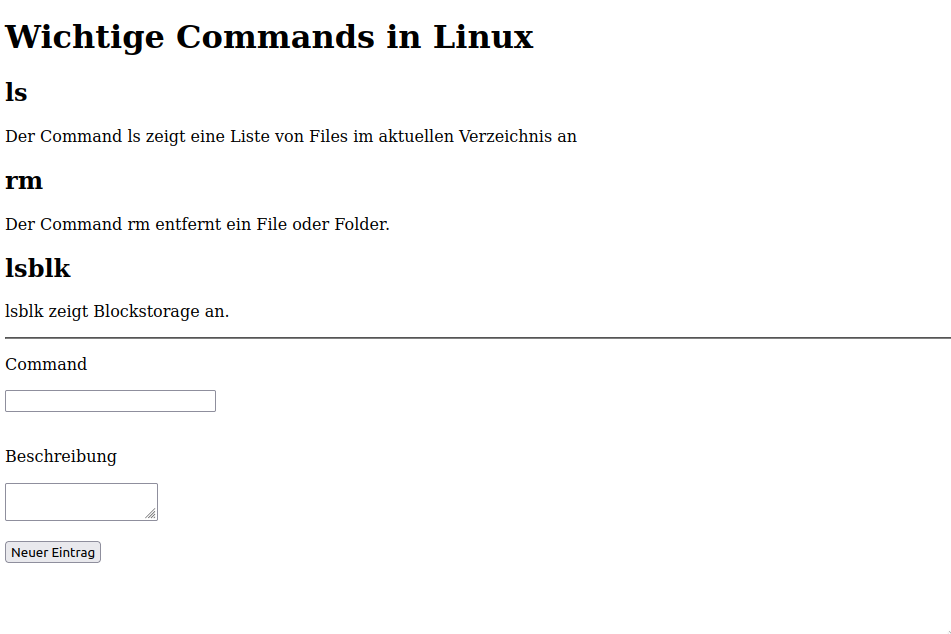
Verwenden Sie hierzu folgende Tags:
h1h2brphrtextareainputmittype="text"button
Schauen Sie sich die jeweiligen Tags auf der W3C Webseite an: https://www.w3schools.com/tags
Firefox / Chrome Inspector
Nach dem Sie die Seite geöffnet haben, können Sie diese in Firefox mit den Debug Tools genauer inspizieren.
Öffnen Sie hierzu den Inspector mit F12. Verwenden Sie das Hover Tool (Icon mit Mauszeiger) und Clicken Sie auf einen Beschreibungstext der Webseite (z.B.) von rm.
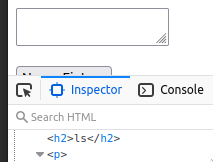
Was wird Ihnen im Quellcode angezeigt? Wenn Sie via Hover mit dem Mauszeiger über das HTML Element fahren, sehen Sie verschieden gefärbte Flächen. Um was könnte es sich dabei handeln?

Baumstruktur des HTML DOM
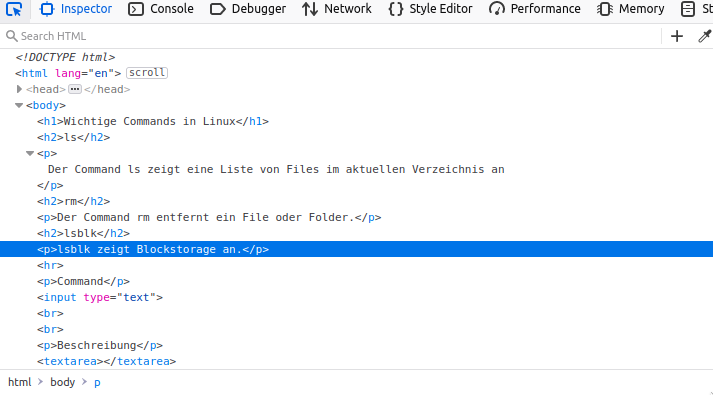
Unter dem HTML DOM versteht man die Baumstruktur der Elemente. Im Inspector lässt sich diese einfach erkennen (Elemente auf- und zuklappen).
In unserem Fall ist der DOM statisch, wir ändern zur Laufzeit die Struktur nicht.
Moderne Applikationen machen gebrauch von der Möglichkeit via Javascript den DOM zur Laufzeit zu manipulieren.
Beispielsweise kann eine Chat App laufend neue Nachrichten auf den Bildschirm hinzufügen. In unserem Beispiel könnten wir den Text im input und textarea auslesen und neue Elemente nach lsblk einfügen.
Bevor wir aber soweit sind, wollen wir zuerst mehr über die Darstellung der Seite verstehen.